진행중인 프로젝트에서 어쩌다보니 ai를 맡게 돼 DL, 데이터분석 등등을 공부하기 시작했다.
저번학기부터 ai 관심 생겼었는데.. 완전 럭키비키잖앙...!!..
현재는 AIHub에서 수집한 샘플 데이터로 이미지 분류 모델을 만들고 있는데
일단 tensorflow를 기반으로 전반적인 ai지식을 얻어야 한다고 생각했다.
그렇게 제대로 강의 보고 만든 첫 cnn모델!

분명 예시 코드를 그대로 돌렸다고 생각했는데..?
어림도 없다. 정확도 11%의 모델을 만들어냈다

일단 실행했던 코드 중 위와같은 warning이 나온 부분이 있길래 이에 대해 찾아보았다.
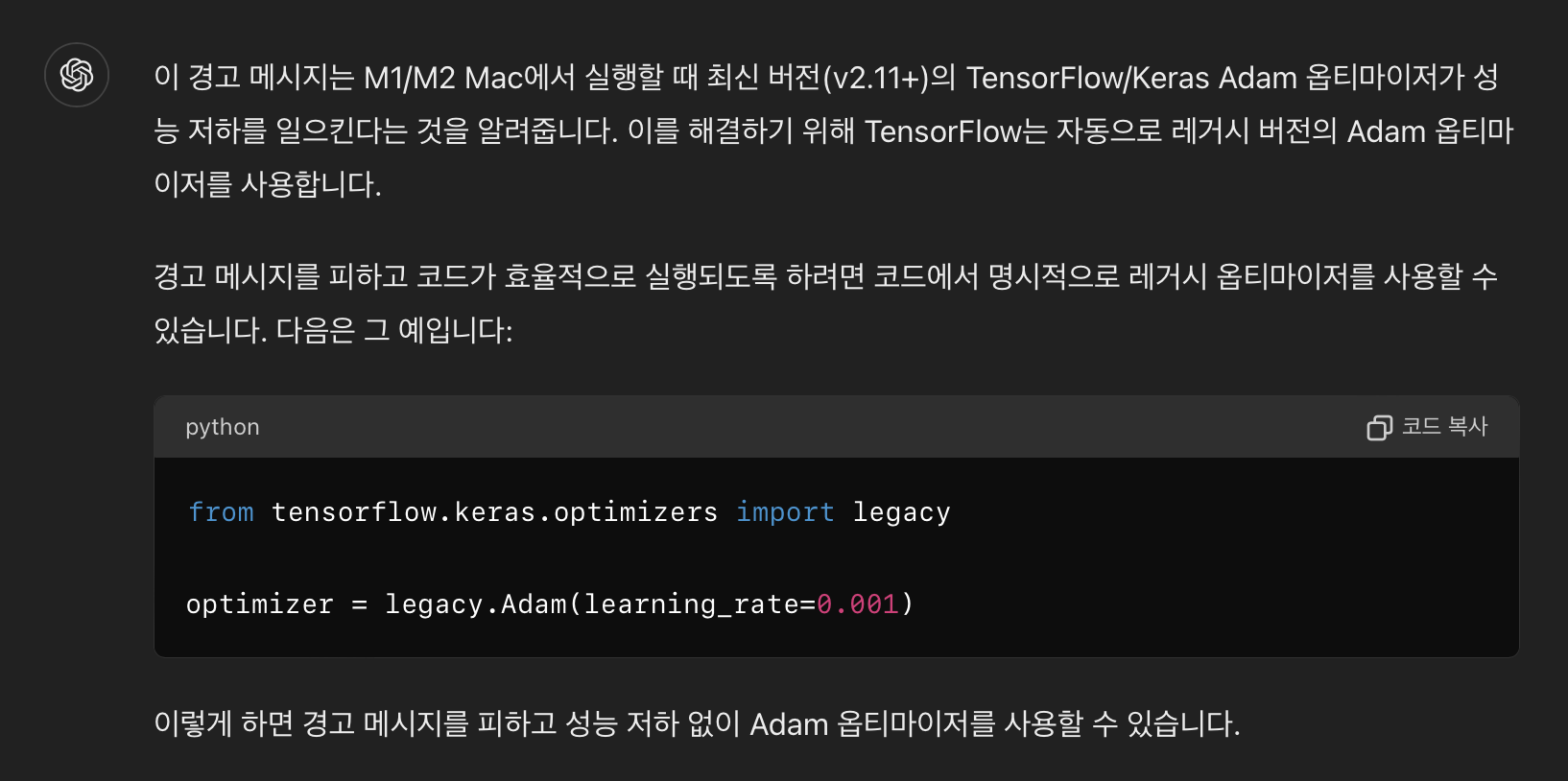
구글링으로는 딱히 정보가 나오지 않았다.
Mac에서 실행할 때 옵티마이저가 성능 저하? 그리고 난 M3인데 ???
- 하드웨어 아키텍처 차이
- 최적화 부족
- 소프트웨어 호환성
- 라이브러리 및 의존성
대충 이러한 이유 때문이라고 한다.
더보기
- 하드웨어 아키텍처 차이:
- Apple의 M1/M2 칩셋은 ARM 기반의 아키텍처를 사용하며, 이는 전통적인 x86 아키텍처와 다르다.
- TensorFlow/Keras는 원래 x86 아키텍처에서 최적화되었기 때문에, ARM 아키텍처에서 동일한 최적화 수준을 달성하기 위해서는 추가적인 작업이 필요하다.
- 최적화 부족:
- TensorFlow/Keras의 최신 버전의 옵티마이저는 M1/M2 칩셋에서 최적화가 충분히 이루어지지 않았을 수 있다. 이는 특정 연산이 M1/M2의 GPU 또는 CPU에서 효율적으로 실행되지 않음을 의미할 수 있다.
- 소프트웨어 호환성:
- TensorFlow와 같은 라이브러리는 새로운 하드웨어에서 성능을 극대화하기 위해 소프트웨어 레벨에서 많은 변경이 필요하다. 이러한 변경은 시간이 걸리며, 최신 버전의 옵티마이저가 M1/M2 칩셋에 최적화되지 않은 상태일 수 있다.
- 라이브러리 및 의존성:
- TensorFlow는 여러 의존성을 가지는 복잡한 라이브러리이다. 최신 버전의 옵티마이저는 특정 의존성 또는 라이브러리의 버전과 충돌하여 성능 저하를 일으킬 수 있다.
물론 결국 모델의 문제는 여기 있지 않았다.
데이터 전처리를 잘못해서 데이터의 개수가 맞지 않았다.

제대로 나온 결과! accuracy도 99.3%가 되었다.
코드 설명
데이터 전처리 부분만 간단하게 정리해 보았다.
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPool2D, Flatten, Dense, Dropout
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(-1,28,28,1)
x_test = x_test.reshape(-1,28,28,1)
print(x_train.shape, x_test.shape)
print(y_train.shape, y_test.shape)
x_train = x_train.astype(np.float32) / 255.0
x_test = x_test.astype(np.float32) / 255.0
- (x_train, y_train),(x_test, y_test) = mnist.load_data():
- MNIST 데이터셋을 다운로드하고 훈련용 데이터(x_train, y_train)와 테스트용 데이터(x_test, y_test)로 분할한다.
- x_train과 x_test는 손글씨 이미지 데이터이고, y_train과 y_test는 해당 이미지의 레이블이다.
- x_train = x_train.reshape(-1, 28, 28, 1):
- x_train 데이터를 4차원 배열로 재구한다. -1은 배치 크기를 유지하며, 각 이미지는 28x28의 크기이고, 채널 수는 1이다. (흑백 이미지)
- -1은 데이터셋의 전체 크기에 따라 자동으로 배치 크기를 정하는 것을 뜻한다.
- x_train = x_train.astype(np.float32) / 255.0:
- x_train 데이터를 float32 형식으로 변환하고, 각 픽셀 값을 255로 나누어 [0, 1] 범위로 정규화한다.
'AI & ML > 딥러닝' 카테고리의 다른 글
| CNN(Convolutional Neural Network) (1) | 2024.11.05 |
|---|---|
| LSTM을 활용한 삼성전자 주가 예측 (1) | 2024.07.17 |

