[트랜스포머를 활용한 자연어 처리] 01. 트랜스포머 소개
인코더 - 디코더 프레임워크

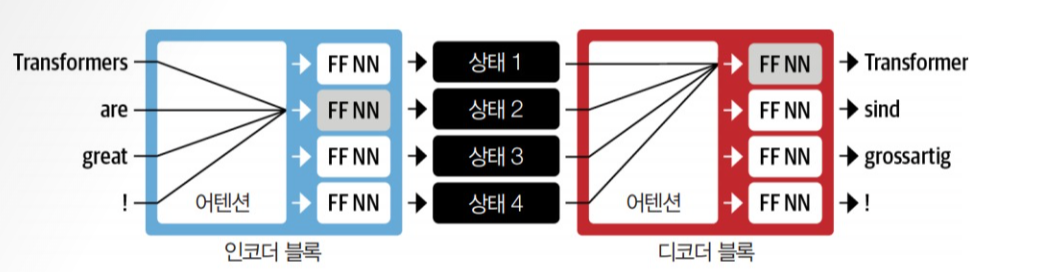
입력 단어는 순차적으로 인코더에 주입되고 출력 단어는 위에서 아래 방향으로 한 번에 하나씩 생성된다.
이 구조는 인코더의 마지막 은닉 상태다 정보 병목이 된다는 약점이 있다. 디코더는 인코더의 마지막 은닉 상태만을 참조해 출력을 만들므로 여기에 전체 입력 시퀀스의 의미가 담겨야 한다. 하나의 표현으로 압축하는 과정에서 시작 부분의 정보가 손실될 가능성이 있어 취약하다.
어텐션 메커니즘
어텐션은 입력 시퀀스에서 은닉 상태를 만들지 않고 스텝마다 인코더에서 디코더가 참고할 은닉 상태를 출력한다는 주요 개념에 기초한다.
즉, 디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고한다는 것이다.
하지만 모든 상태를 동시에 사용하려면 디코더에 많은 입력이 발생하므로 어떤 상태를 먼저 사용할지 우선순위를 정하는 메커니즘이 필요하다. 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 보게 된다.

그림에서 어텐션은 출력 시퀀스에 있는 두 번째 토큰을 예측하는 역할을 한다.
트랜스포머는 모델링 패러다임을 바꿨다. 순환을 모두 없애고 셀프 어텐션이라는 특별한 형태의 어텐션에 전적으로 의지하게 된 것이다.
신경망의 같은 층에 있는 모든 상태에 대해서 어텐션을 작동시키는 방식이다. 후에 자세히 다루겠다.
NLP의 전이 학습
모델은 바디와 헤드로 나뉜다. 바디의 가중치는 훈련하는 동안 원래 도메인에서 다양한 특성을 학습하고, 이 가중치를 사용해 새로운 작업을 위한 모델을 초기화한다.

바디와 헤드
1. 바디 (Body):
- 역할: 모델의 주요 작업을 처리하는 부분이다. 보통은 언어 데이터를 이해하고 표현하는 데 핵심적인 역할을 한다.
- 구성 요소: 주로 여러 층(layer)으로 구성된 신경망. 트랜스포머의 경우 여러 인코더 또는 디코더 층들이 여기에 해당한다.
2. 헤드 (Head):
- 역할: 바디가 처리한 정보를 최종적으로 원하는 출력 형태로 변환하는 역할을 한다. 모델이 훈련된 목표(예: 텍스트 분류, 번역, 질의응답 등)에 따라 바디의 출력을 구체적인 답으로 바꾼다.
- 구성 요소: 출력층(Output layer), 보통 Dense layer 또는 Linear layer가 해당된다. 헤드는 모델이 주어진 작업에 따라 다르게 설계될 수 있다.
예시
- 바디: 텍스트를 분석하고 다양한 특징을 추출한다.
- 헤드: 이 정보를 바탕으로, 예를 들어 '긍정'인지 '부정'인지 카테고리로 분류하는 결과를 만든다.
컴퓨터 비전에서는 전이 학습이 표준이 됐지만, NLP에서 전이 학습과 유사한 사전 훈련 과정이 무엇인지는 수년간 특정하지 못했다. NLP 애플리케이션은 성능을 높이기 위해 레이블링된 대량의 데이터를 사용했지만, CV의 성능보다 훨씬 낮았다.
2017년와 2018년, 몇몇 연구 단체가 NLP에서 전이 학습을 수행하는 새 방식을 제안했다.
사전 훈련
초기 훈련의 목표는 매우 간단하다. 이전 단어를 바탕으로 다음 단어를 예측하는 것이다. 이 작업을 언어 모델링이라 한다. 레이블링된 데이터가 필요하지 않으며 위키피디아 같은 소스에 있는 텍스트를 활용한다.
도메인 적응
도메인 내 말뭉치에 적응시킨다. 여전히 언어 모델링을 사용하지만 이제 모델은 타깃 말뭉치에 있는 다음 단어를 예측한다.
파인 튜닝
언어 모델을 타깃 작업을 위한 분류 층과 함께 미세 튜닝한다.